
はじめに
「皆さんは途中まで読んでいた本を続きから読みたい時、どうしますか?」
普通だったら、しおりを挟んでおいて、そこから読み始めますよね?
自分は前回読んだページまで、1ページ目から1枚ずつめくっていた みたいです。。。
業務で発生した事象
- 約1000万件のデータをAテーブルからBテーブルにデータ移行するクエリを実行していました。
- 大量データなので、指定件数分取得してBulk insertする処理を、全件分繰り返すという処理でした。
- クエリを実行してみると、登録された件数が増えるほど処理時間が増加していき、全件処理するのに24時間以上かかっていました。
使用していたSELECT文
指定件数分取得するクエリでは以下のようなSELECT文を使用していました。
SELECT * FROM A LIMIT "指定件数" OFFSET "前回までに処理した件数";パフォーマンス低下の原因
OFFSETの処理が原因
パフォーマンス低下の原因は、LIMIT OFFSETの処理でした。
全件スキャンと読み飛ばし
OFFSETは、指定された行数だけ結果セットの先頭からデータを読み飛ばす処理を行う。- たとえば、
OFFSET 10000と指定した場合、データベースは内部的に少なくとも 10000 行のデータを一旦取得し、その後で最初の 10000 行を破棄してから残りのデータを返す。 - 冒頭の「1ページ目から1枚ずつめくっていた」とは、このこと
インデックスの恩恵を受けにくい
OFFSETは、インデックスを使って特定の行に直接アクセスするのではなく、順番に読み飛ばしていくため、インデックスの効果が薄れてしまう。- 特にオフセットの値が大きくなるほど、この傾向が顕著になる。
OFFSET処理のイメージ
- 例えるなら、10000 ページある本の 9001 ページ目から 10 ページを読む場合、
OFFSETは最初の 9000 ページをすべてめくってから目的のページにたどり着くようなイメージ。 - 直接 9001 ページを開く方が圧倒的に効率的。(しおりを使ったほうがいい。)
対策
シークメソッドの利用
シークメソッドとは
- データベースで大量のデータをページネーションする際に
OFFSETを使用する代わりに、- 特定のカラムの値に基づいてデータの範囲を指定して効率的に目的のデータを取得する手法。
OFFSETのように指定された件数をスキップするのではなく、- 「特定の条件を満たすレコード以降のデータを取得する」というアプローチを取ります。
- つまり、
- 「しおりを挟んでおいて、そこから読みなおす」ということ
シークメソッドの基本
- ソートキーとなるカラム指定
- ページングの順序を決めるカラム(ID, タイムスタンプなど)
- インデックスが設定されていること
- WHERE句による範囲指定
- 前の検索範囲の最後のレコードのソートキーの値を利用して、次のページのデータの開始点を指定する。
- ORDER BYによる整列
- 並べ替えの順序を確定的にするために整列する。
クエリ
ソートキーは、idとします
SELECT * FROM テーブル
WHERE id > "前回取得した最後のレコードのid" ORDER BY id修正した結果
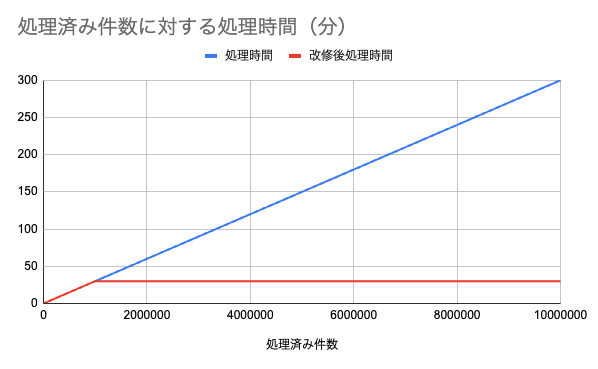
- データ移行時のSELECT文に使用していたLIMIT OFFSETを、シークメソッドに修正した結果
- 処理時間が4時間半になりました。
- 修正前と比べると
- 約20時間短縮されました!
- 1000000件ごとの処理時間を確認すると、改修前は件数が増えるにつれて処理時間が長くなっていましたが
- 改修後は件数が増えても処理時間は一定になりました。
まとめると
- 大量データに対して
LIMITとOFFSETを使用した場合の遅延は、主にOFFSETが指定された行数だけデータを読み飛ばすという非効率な処理に起因する。 - 必要なデータだけを効率的に抽出するのではなく、不要なデータまで一旦処理する必要があるため、処理時間が増加してしまう。
- そのため、シークメソッドやインデックスの活用など、
OFFSETを避ける、または効率化するアプローチが重要になる。
さいごに
本を読むときは、しおりを挟みましょう

